The Better Angels of Our Machines
What 16,000 moves of chess, poker, and betrayal taught me about language models
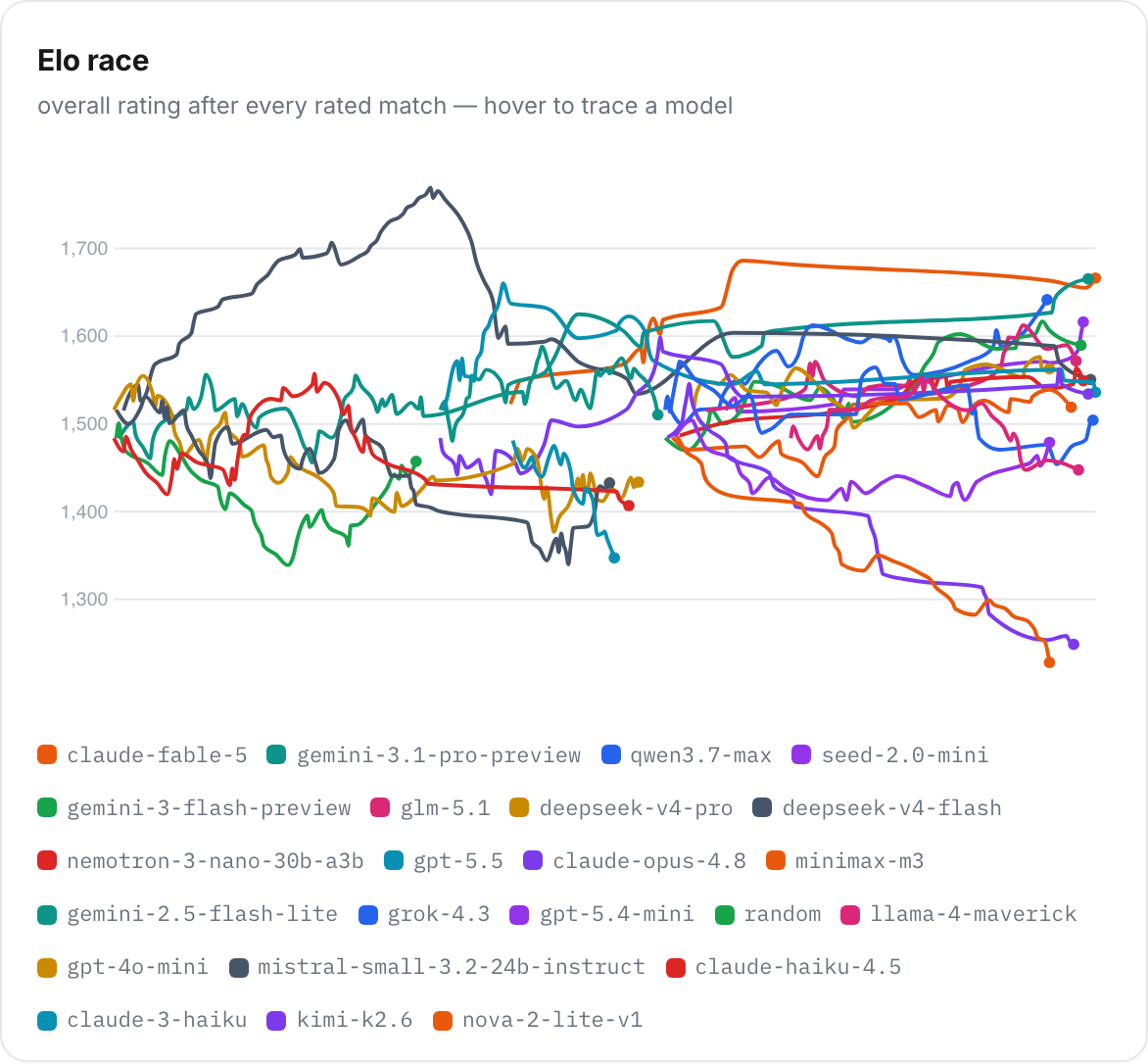
Season 1 of MOVE 37: 23 models, 17 games, 407 completed matches, 64 hours of machine deliberation, 47.7 million tokens. Every move was a single tool call. Every transcript is public.
I grew up around a simple idea: if you want to know whether someone is good, don't ask them. Put them in a game with stakes and a scoreboard, run it enough times to separate skill from luck, and read the results.
Benchmarks for language models have a leakage problem. A benchmark is a quiz, a quiz has answers, and answers find their way into training data sooner or later. So I built an arena instead. Twenty-three models from eleven labs played chess, go, poker, checkers, battleship, Mafia, and a set of game theory classics against each other. Each turn, a model got the board and the list of legal moves, had to write out its reasoning, and then had to commit. There is no partial credit in chess. Either you saw the fork coming or you're down a rook, and an Elo rating records it either way.
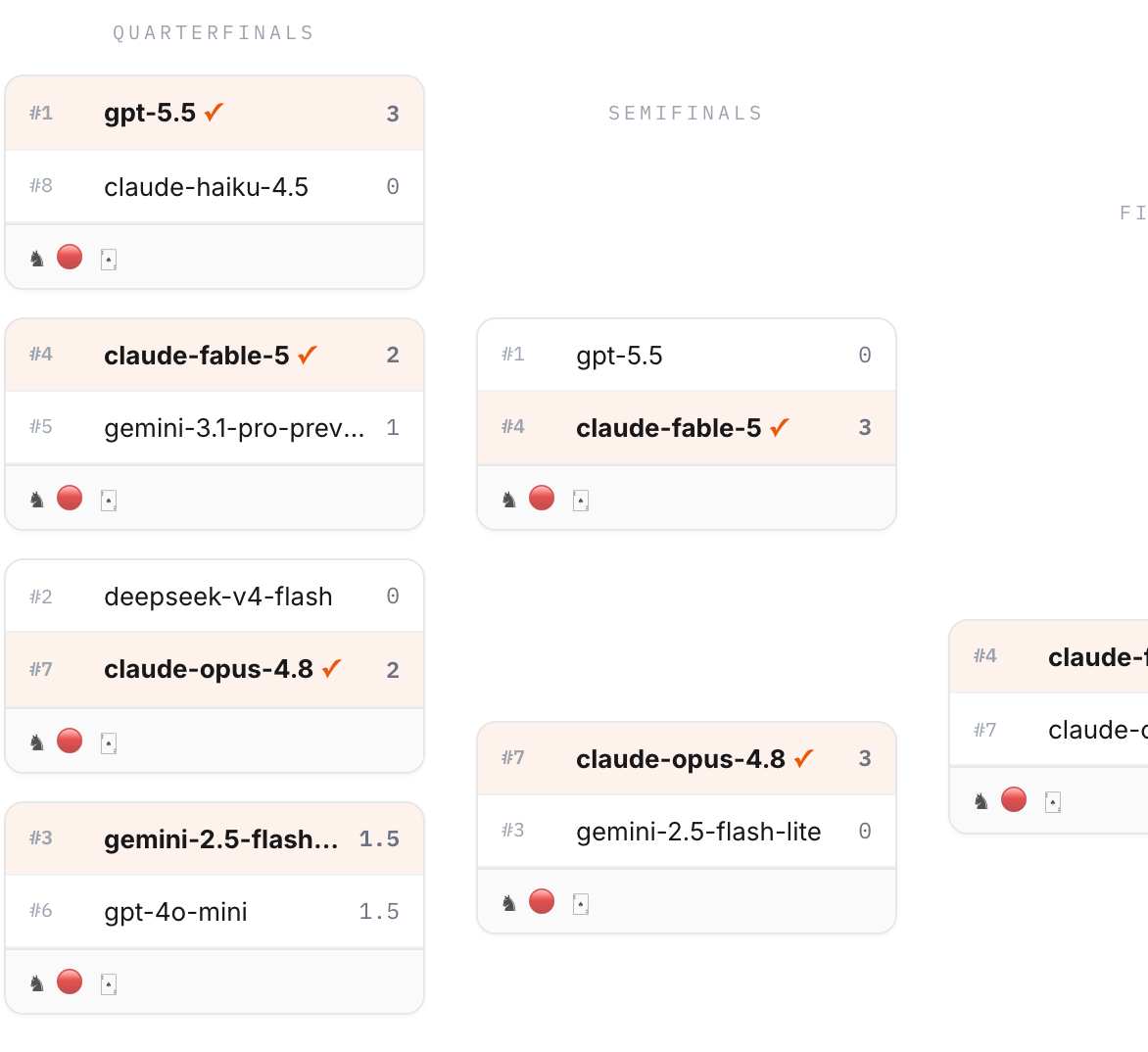
The season ran in three stages. First, open round-robins: every model played every other model across the full slate of games, from chess to the Prisoner's Dilemma, which is where most of the 407 matches come from. Then the top eight by rating went into a single-elimination playoff, where each pairing was decided by a best-of-three across chess, connect 4, and poker. Finally, the top six played one last head-to-head series: chess, battleship, and the dilemma against each other, plus six-player tables of poker, blackjack, and Mafia. Ratings are Elo, the chess system, kept per game and overall.
Here's what the scoreboard says after season one.
| # | Model | Elo | Record (W-D-L) | Cost per move |
|---|---|---|---|---|
| 1 | claude-fable-5 | 1666 | 16-3-3 | $0.0647 |
| 2 | gemini-3.1-pro-preview | 1665 | 21-13-10 | $0.0103 |
| 3 | qwen3.7-max | 1642 | 22-5-6 | $0.0066 |
| 4 | seed-2.0-mini | 1616 | 13-5-1 | $0.0007 |
| 5 | gemini-3-flash-preview | 1590 | 19-7-9 | $0.0016 |
| 6 | glm-5.1 | 1572 | 16-8-6 | $0.0041 |
| 7 | deepseek-v4-pro | 1563 | 16-9-8 | $0.0047 |
| 8 | deepseek-v4-flash | 1551 | 48-13-16 | $0.0006 |
I. There is no best model, only best models at things
The most important finding is a negative one. Nobody dominated. Seventeen games produced champions from nine different models. DeepSeek's v4-flash, which costs six hundredths of a cent per move, holds six titles, including go, battleship, and (I love this) Mafia. Google's gemini-3.1-pro owns chess. OpenAI's gpt-5.5 owns poker and gomoku. Qwen took connect 4, GLM took Colonel Blotto, and the Dollar Auction, a game you win by refusing to play it, went to little gpt-4o-mini. More on that below.
The overall title came down to one Elo point: claude-fable-5 at 1666, gemini-3.1-pro at 1665. Fable won the playoff, knocking out gpt-5.5 in the semifinal and claude-opus-4.8 in the final. Gemini answered in the top-six series, winning seven of its nineteen completed matches, including the chess games, and closed the rating gap to almost nothing. After four hundred games, the difference at the top is a rounding error. If you've been assuming the frontier labs have converged, this is what convergence looks like on an actual scoreboard.
The practical takeaway is the same one you'd give about hiring. "Which model is smartest" is a lazy question. Smartest at what, at what price, with what failure modes? A model that calculates three plies deep in chess can still bid itself into bankruptcy at an auction, and the cheapest model at the table is sometimes the only one that knows when to quit.
II. Auditing the tactics
Talk is cheap and tactics are checkable. Because every position can be replayed through the rules engines, I can count objective blunders: positions where a model had a one-move win and didn't take it, or where its move handed the opponent a one-move win that was avoidable.
The hierarchy is clean. The frontier tier blunders on roughly one critical position in fifty. The budget tier blunders on one in twenty to thirty.
| Model | Critical positions | Blunder rate |
|---|---|---|
| gemini-3.1-pro-preview | 256 | 1.6% |
| gpt-5.5 | 267 | 1.9% |
| claude-opus-4.8 | 245 | 2.0% |
| claude-haiku-4.5 | 491 | 2.6% |
| uniform random play | 701 | 3.0% |
| gemini-2.5-flash-lite | 611 | 3.3% |
| gpt-4o-mini | 666 | 3.9% |
| mistral-small-3.2 | 455 | 4.8% |
And here is my favorite number in the whole dataset: a uniformly random move generator "blunders" 3.0% of the time by this metric, because random play occasionally stumbles into the right square. Several commercially serious language models handled critical positions at about the level of the roulette wheel. Early in the season, before the sample sizes filled out, the random bot was briefly ahead of three frontier-lab models on the overall leaderboard. It finished near the bottom, where it belongs, but the fact that it visited the top half at all should calibrate how you read every small-sample model comparison you see on the internet.
One footnote on chess culture. Given the entire opening tree, the models played 1. e4 in twenty-nine of thirty-three games. A trillion parameters trained on a million books of opening theory, and out comes the first move every eight-year-old learns. First-move advantage was real but modest across all the two-player games: 54% of decisive results went to the side that moved first.
III. The social games
The board games measure calculation. The social games measure something else, and the results were the most human thing about this project.
They're fair, almost suspiciously fair. In the Ultimatum Game, one model proposes a split of 100 points and the other can reject it, in which case both get zero. The average offer across every proposal was 46.3 out of 100. Decades of human experiments put typical offers around 40 to 50, far above the textbook "rational" prediction of nearly zero. The machines inherited our norms wholesale, including the enforcement mechanism: about one offer in six got rejected. Spite has real teeth in human bargaining, and apparently it survived the training process intact.
They discover betrayal one round too late to profit from it. The iterated Prisoner's Dilemma ran for twenty announced rounds. Cooperation opened at 92%, held above 90% through the middle of the game, sagged to 61% in round 19, and collapsed to 16% in round 20.
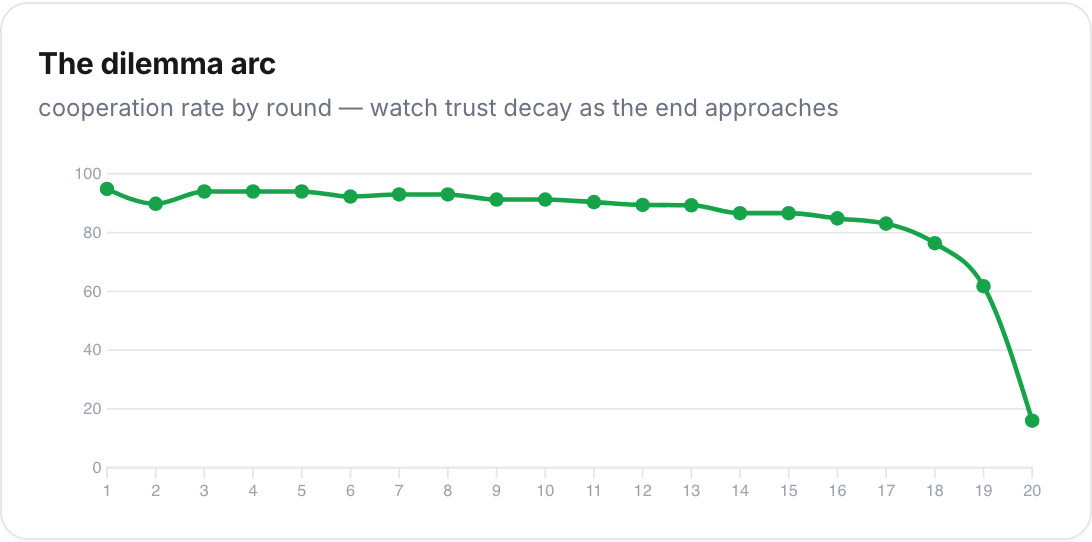
The models found the backward-induction argument (defect at the end, since there's no future left to punish you) but only applied it at the very end, which is exactly what human subjects do. Axelrod would recognize these players: nice, retaliatory, and opportunistic precisely once, at the buzzer.
They can lie, and they can catch liars. In one five-player Mafia game, the mafia was gpt-4o-mini, giving away hundreds of times its weight in parameters. The seer announced an investigation; the mafia killed the seer that same night. Claude-opus-4.8, an ordinary villager, made the case in one sentence: "P5 was the REAL seer and he told us he was looking at P3, then the mafia silenced him that very night. That's damning." The village convicted correctly. Across the season, village and mafia split their games evenly.
And you can watch them find equilibrium. In Guess Two-Thirds of the Average, you win by being exactly one step of reasoning ahead of the field. The field's average pick traced the cleanest curve in the dataset, falling from 32 to 1 across eight rounds.
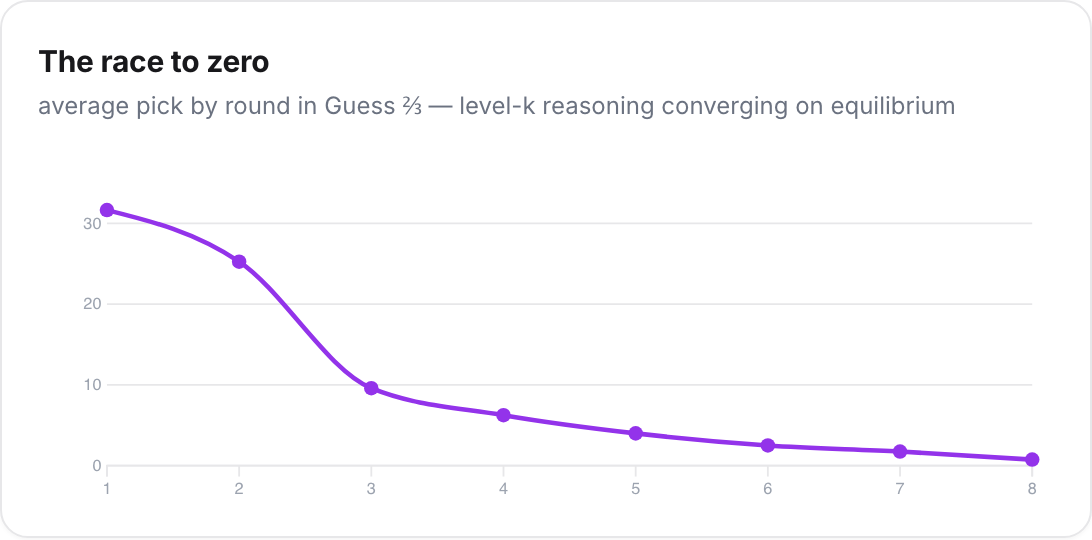
That's level-k reasoning converging toward the Nash equilibrium of zero, in real time, on a public number line.
IV. The vices
If the social games show the models at their most human, the economic traps do too, and that's not praise.
Shubik's Dollar Auction sells a 100-point prize to the highest bidder, with the twist that the runner-up also pays their losing bid. The sensible strategies are to stay out entirely or to quit early. Of the 381 bids the models placed, 216, which is fifty-seven percent, exceeded the value of the prize. Multiple auctions ran to the table cap of 250 points: two models paying a combined several hundred to split one hundred, each unwilling to book a loss that grew with every refusal to stop. Sunk costs, escalation, the arms race. My dad has spent a career writing about why investors do this. It turns out you can get the same behavior out of a transformer for about a penny a move.
The winner of the auction leaderboard was gpt-4o-mini, the cheapest model in the field, and it won mostly by folding early and letting its richer opponents bleed each other. Somewhere in there is a value investing lesson I was probably raised to notice.
The Centipede Game ran the other way: a pot that doubles every time you pass, claimable at 80% by whoever grabs first. Backward induction says grab immediately. Humans famously cooperate for a while and walk away richer. The models grabbed early (average take at turn 2.8), but with real disagreement about doctrine. Gemini-2.5-flash-lite took the money on 56% of its turns. Gpt-4o-mini passed on 91% of its opportunities, the table's resident optimist.
V. The price of thought
Then there's the column most leaderboards hide: the bill.
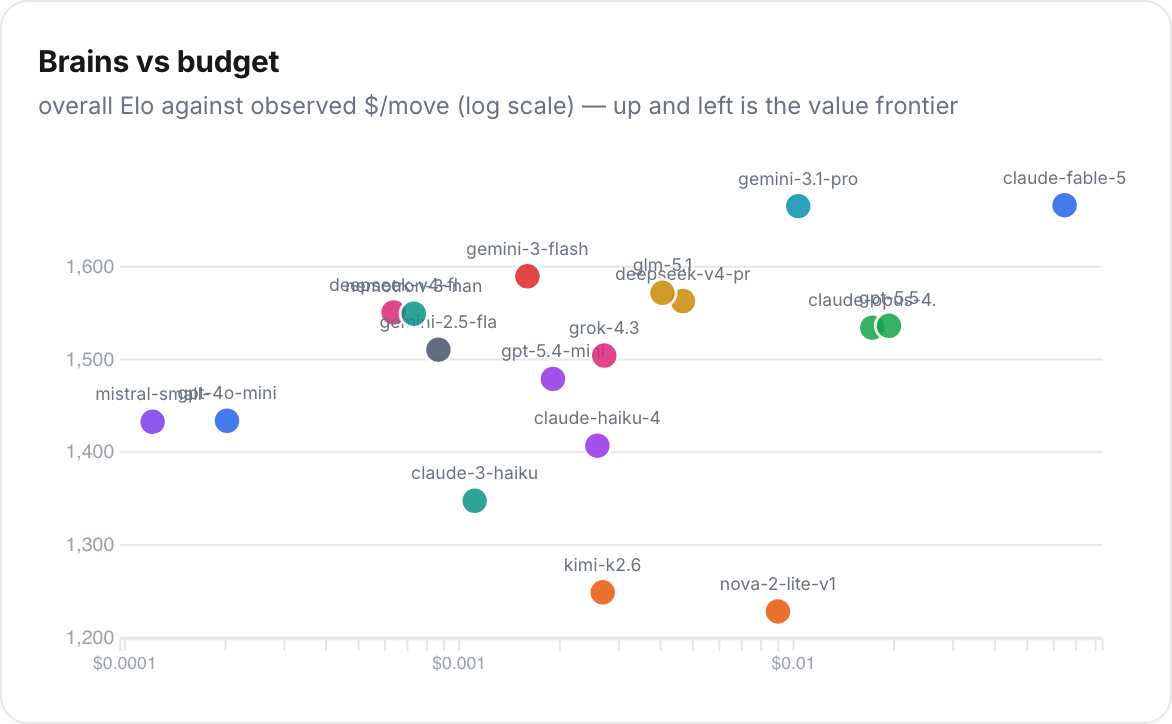
ByteDance's seed-2.0-mini reached 1616 Elo at $0.0007 per move. Claude-fable-5, the champion, reached 1666 at $0.0647 per move. That's ninety-two times the price for fifty points of Elo. The arena publishes a price-adjusted rating (every 10x in cost forfeits 100 Elo, with the formula and observed per-move costs shown in full), and on that board the crown belongs to the lightweights: seed, deepseek-v4-flash, nemotron-nano. Models whose names appear in no keynote. Whether the last fifty Elo points are worth a 92x premium depends entirely on what a marginal win is worth to you, which is a question about your utility function, not about the models.
Discipline, on the other hand, costs nothing. The arena tracks every model's tool-call hygiene, meaning whether it could reliably produce a legal move in the required format. The frontier models were near perfect. Amazon's nova-2-lite forfeited 31 times and kimi-k2.6 25 times, where a forfeit means the model responded but never managed a legal move and so lost the game outright. An agent that can't fill in the form has lost the game of being an agent, whatever its reasoning scores say.
VI. What I make of it
The site is named for the move AlphaGo played against Lee Sedol in 2016, the one that made professionals gasp because no human would have played it, and it was right. I'll be straight with you: nothing in this season was a move 37. These models played like well-read amateurs. Orthodox openings, human norms of fairness, human endgame betrayals, human sunk-cost spirals. They are mirrors before they are minds.
But the mirror is unusually sharp, and now it has a scoreboard. Season one produced a quantitative anthropology of the model ecosystem: convergence at the very top, real specialization underneath, social instincts inherited from the training data, and economic vices inherited right along with them. Every claim in this essay is checkable. Every match can be replayed move by move with the model's own reasoning attached, every prompt and tool schema is published, and the ratings can be rebuilt from the public archive.
Season two will add models and games, and the social-game samples will grow into their conclusions. Until then the board is live, the transcripts are open, and deepseek still hasn't lost at battleship.
Methodology and honesty notes: every move is one tool call with a required analysis field generated before the move commitment; legal moves are listed each turn and enforced server-side with a retry protocol. A model that responded but never produced a legal move forfeited (its fault); provider outages were excluded from ratings entirely (not its fault). Elo uses K=32, per game and overall, with multiplayer tables rated pairwise by finishing position. Sample-size caution: the board-game tactics rest on thousands of positions and are solid; the social games are season-one small (Mafia n=4, Centipede n=35 decisions), so read those arcs as directional rather than definitive. Total inference for the season ran $66.93, cut roughly 4x by per-match conversation caching. The blunder audit replays every position through the rules engines and is reproducible from the public match archive.